这是很多视频号新手常问的问题。
大家已经能通过ChatGPT、Kimi等AI工具在几分钟内生成一篇文案,甚至更快。但问题来了:每天都有很多文案,却无法轻松转成视频内容。想提高获客效率,可是时间和精力都花在视频制作上,问题就卡在这里。
好消息是,有办法可以解决这个问题——一种既能批量生成多条视频,又保证每条视频都是原创、不容易被查重的策略,轻松满足多平台多账号的视频内容更新需求。
先看看几个视频号后台的实际播放数据:
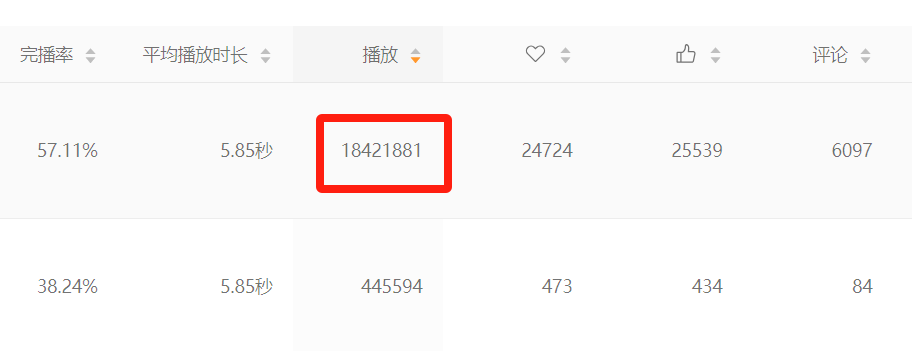
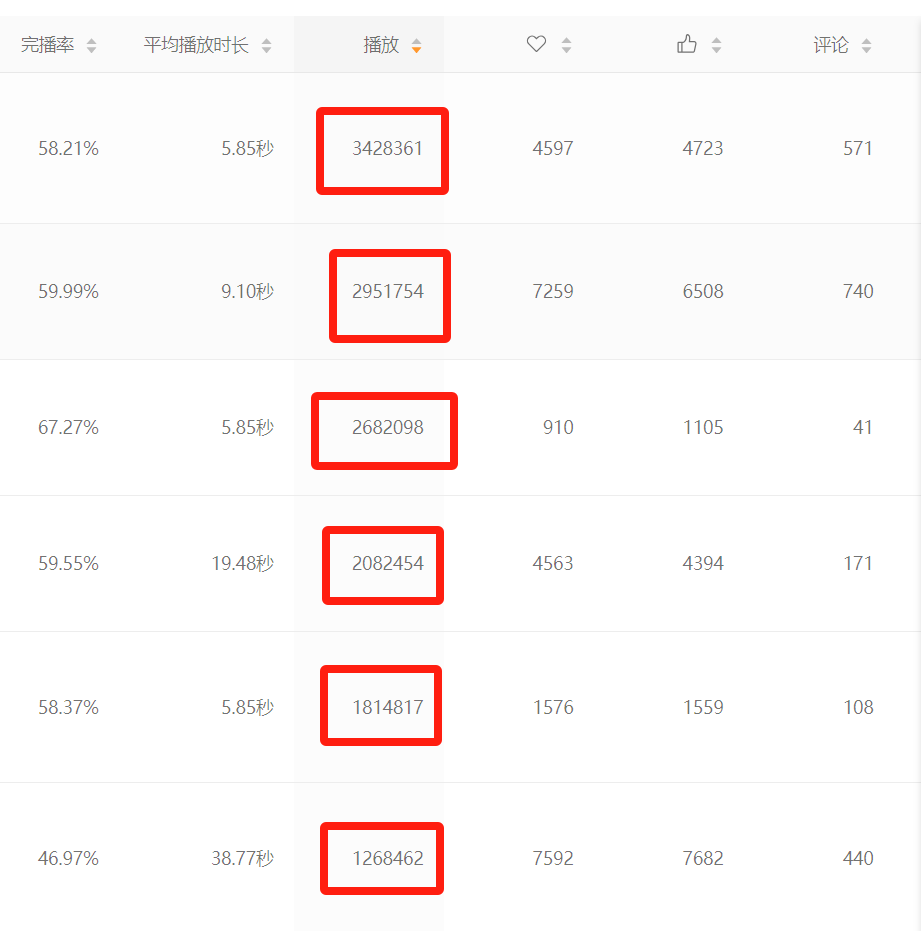
咱们先理一理思路,看看解决这个问题的关键所在。
一般来说,视频,特别是以口播内容为核心的视频,其成败往往取决于两个因素:
关键因素1:内容
内容是视频的灵魂,尤其是口播类视频。
为什么是“口播”?因为它的内容传达直观、真实,有利于拉近观众和创作者之间的距离。这种内容的核心价值就在于能清晰地传达信息,并与观众建立连接。
对于大多数希望通过视频获客、变现的用户来说,口播就像一种软性广告,用传达资讯和科普知识的方式,让内容具有商业价值。
口播内容方式,既不显得突兀,又能将产品、服务信息无形中传达给受众。与那些想通过视频平台出名的人不同,这类内容创作者更多关注实际的商业转化。
关键因素2:形式
形式上,最直接的方式就是拍摄真人的口播。我们可以拍正脸、侧脸,还可以搭档互动,这种方式简洁直接。或者,拍摄环境场景,比如工厂、线下门店等,这种方式在某些行业(如餐饮)也很有效。
最通用的方式其实就是拍摄“老板自己”,不过问题往往出在镜头表现力和时间上。
一些人一对镜头就会显得僵硬、嘴结巴,这个很常见。另一些人则事务缠身,时间安排上无法配合日常拍摄。因此,老板亲自拍摄虽好,但操作起来并不总是顺利。
看到这些问题,解决方案自然也就显而易见了。既然内容和形式都有需求,那么内容可以通过AI文案工具解决,而视频形式的难题则可以靠高仿真数字人来解决。数字人可以为我们提供一种几乎以假乱真的效果,而且成本还低。
下面,分享一下具体的操作步骤:
1)多场景数字人建模
首先,我们可以利用数字人来制作视频,可以在不同场景拍摄不同的服装和姿势,这样就会有多种素材供后续合成使用。
比如,我们可以在多种场景里让数字人换上不同的衣服,拍摄一批素材。这些素材将在最终确定合成视频时才会产生费用。
换句话说,数字人可以在前期多次建模、拍摄,而不用担心每次都产生额外费用。这样既经济又灵活,为后续的视频生成奠定了基础。
(如下图所示,展示了多个场景和人物模型的搭配。)

2)AI文案片段化制作
在文案上,提醒大家一点:我们不应该把一个完整的文案当作一个整体,而应该把它拆分成开头、主体和结尾三个片段。
传统拍摄时,我们通常会一气呵成地录完一条完整文案。但在使用数字人时,我们可以将文案拆分为不同的段落单独生成视频。
比如,我们可以将文案分成开头、主体和结尾三个部分,每部分单独生成视频片段。这样做的好处是可以进行更多组合,让视频呈现更多样化。
可以简单理解为,我们最后会得到三种不同的视频:开头、主体和结尾。然后我们可以利用这些不同的片段来与场景进行组合,形成大量的视频内容。
这种组合方式让我们从内容到形式都能实现多样化呈现,增加了视频的原创性,也让账号内容更丰富。
对比真人拍摄,数字人的优势明显,不需要耗费大量的时间和人力成本。现实中可能需要几个小时甚至几个人完成的工作,现在通过数字人几分钟就能完成。
常见问题
这种方式的批量生成视频会让很多人担心效果、审核和查重的问题。下面总结了一些常见问题,帮助大家消除疑虑。
1. 这种视频能过审吗?
答案是肯定的。发布的视频几乎都有数字人制作的内容,从未遇到过审核问题。
2. 这种视频会被查重吗?
如果某条视频播放量超过50万,可能会因文案进入平台数据库而被查重,但在这个方案中,画面本身不会被查重,因为每条视频都是独一无二的。
3. 数字人视频会被平台限流吗?
合法数字人生成的视频文件会有“数字人水印”,防止被用于不正当用途。但在平台上没有限流,平台真正关心的是内容的质量,而不是形式。
抖音平台甚至在推广自家的数字人制作工具,可见对数字人视频并不排斥。
AI生成文案+数字人口播,这是目前最高效的低成本制作视频方式。对小伙伴们来说,不仅解决了视频制作的瓶颈,还降低了时间和人力成本,让内容创作更加高效。
一般来说,视频,特别是以口播内容为核心的视频,其成败往往取决于两个因素:
1)多场景数字人建模





